How large-language models are quietly redrawing the Internet’s value chain — and what businesses should do next
Ben Thompson’s Aggregation Theory (Stratechery, 2015 & 2017) explained why the companies that own demand — Google, Facebook, Amazon — ended up with all the power once the web made distribution free.¹ Today, large-language models (LLMs) push that logic further: they make the production of generic text, images, and even code effectively free. That shift forces every site, service, and marketplace to ask a blunt question:
Are we someone’s easily replaceable input, or are we the irreplaceable endpoint an AI must call?
1. From “content is king” to “content is context”
For a quarter-century search engines rewarded volume. Publish another “10 best CRMs” listicle, earn a few backlinks, buy search or retargeting ads — and you were in business. LLMs wreck that bargain. When ChatGPT, Gemini or Perplexity can synthesise a persuasive answer on demand, the marginal value of yet-another article drops toward zero.
That doesn’t kill information; it simply shifts the value upstream to assets the models cannot hallucinate or easily replace:
- Unique, dynamic data — live train locations, hourly hotel inventory, tomorrow’s wheat futures.
- Direct customer relationships — bookings, log-ins, payments the model can’t complete itself.
- Physical or highly specialised services — a dentist, an electrician, a three-Michelin-star dining room.
Every other intermediary risks being collapsed into the answer box.
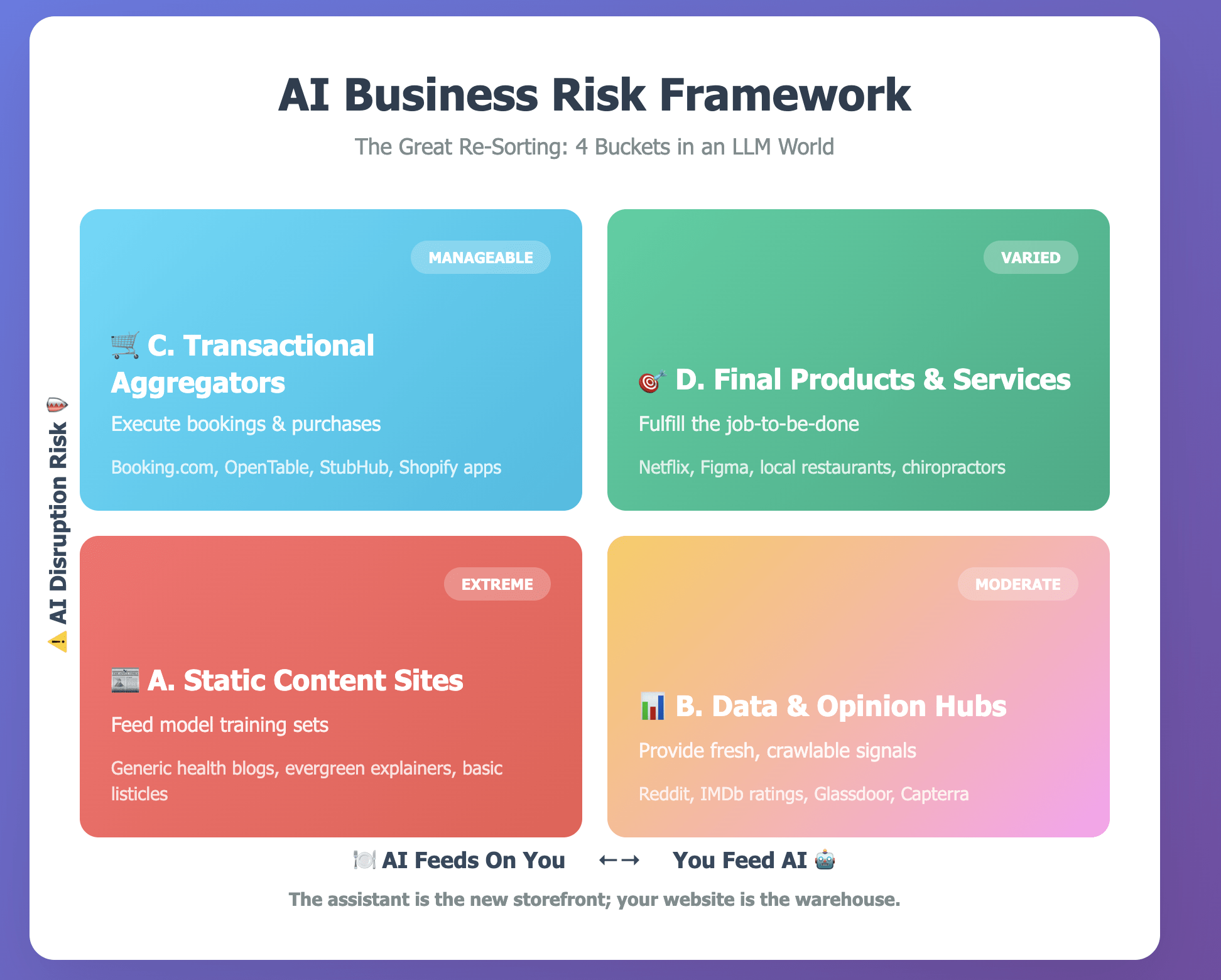
2. Four buckets in an LLM world
Think of the web’s businesses as four rough buckets. The labels are mine, but the underlying logic follows Thompson’s framework.
|
Bucket |
Role vs. LLMs |
Typical examples |
Risk profile |
|---|---|---|---|
|
A. Static-content sites |
Feed model training sets; answers are synthesised directly |
Generic health blogs, evergreen information explainers |
Extreme — traffic & ad yield decay first, revenue later |
|
B. Data & opinion hubs |
Provide fresh, crawlable signals models can’t infer |
Capterra, Glassdoor, Reddit, IMDb ratings |
Moderate — must stay freshest and most trusted |
|
C. Transactional aggregators |
Complement the model by executing the booking, purchase, hire |
Booking.com, OpenTable, StubHub, Shopify marketplace apps |
Manageable — intent concentrates; competition intensifies |
|
D. Final products & services |
Ultimately fulfil the user’s job-to-be-done |
Netflix, Figma, a local chiropractor, a boutique hotel |
Varied — physical services durable; digital utilities face copy risk (see Stack Overflow) |
Bucket D is not a permanent safe harbour. Stack Overflow is the product — yet Claude Code or Copilot-style code completion chips away at its reason to exist. By contrast, a neighbourhood restaurant faces a different pressure: AI may redistribute demand (“Book me the highest-rated tapas bar within two kilometres”), but a language model will not be frying calamari any time soon.
3. A mini-story: when the sign-up form moves to ChatGPT
Vercel — a developer-tool company adored for its Next.js hosting platform — recently shared in their blog that one in ten new sign-ups now arrives straight from ChatGPT’s answers. Ten percent of net-new users is routed through a conversational interface that didn’t exist >18 months ago. That single data point captures the re-sorting:
- The research phase is collapsing into the chat box.
- The hand-off goes not through Google Search, but will go through an MCP call.
- The winner is whichever service the model trusts to fulfil the intent.
If an engineering-heavy firm like Vercel can see 10 % of conversions siphoned into the AI layer this fast, every consumer, B2B, and local-service brand should assume its funnel is next.
4. Why freshness beats mere authority
Classic SEO worshipped PageRank. LLM answers reward recency plus structure. That is why GitHub commits, live flight prices, or a Reddit thread posted thirty minutes ago appear in answers more often than a dusty Encyclopaedia Britannica entry.
This is also why xAI is partnering with Telegram on a deal that seems to make no sense. High engagement front-ends are in high demand in the LLM world. X is key for real-time information, but has few users.
If your data changes, the retrieval layer must ping you every time (in fact, they do, check your log files). If it never changes — Aristotle’s quotes, last year’s mattress review — it is swallowed once and forgotten.
5. Strategy, bucket by bucket
5.1 Static-content publishers
Stop spraying undifferentiated pixels. Pivot to proprietary data (original surveys, lab tests, academic collaborations) and license it or expose an API.
5.2 Data & opinion hubs
Monetise indirect value: citations are the new backlinks. Charge suppliers for “LLM visibility health” even as blue-link clicks shrink. Layer on interactive tools that chatbots cannot replicate inline.
5.3 Transactional aggregators
Deepen the “last-mile” complexity — loyalty tiers, insurance add-ons, friction-free refunds. Negotiate exclusive inventory or pricing so the assistant must hand off to you.
5.4 Final products & services
Instrument public perception: structured docs, changelogs, thought-leadership podcasts and Wikipedia pages are raw material for answers. Offer official MCPs for LLMs to consume so that your service is the default executor.
6. “But we’re the product — surely we’re safe?”
Not necessarily. Stack Overflow faces existential substitution; Shutterstock combats Midjourney. The physical world is safer but not immune — price compression arrives even if the service itself remains irreplaceable.
Think of risk this way:
- Replacement risk for purely digital utilities.
- Margin risk for physical or specialised providers (restaurants, plumbers, architects) as assistants comparison-shop on the user’s behalf.
- Distribution risk for everyone — because the front-end has moved.
7. The interface shift: AI models are your new front-end
A few years ago SEO conferences buzzed, “Some day we’ll pass all our structured data straight to the search engine via Schema.org.” We were half right. We are handing data to machines — but via 24/7 scraping, not neat JSON-ld alone. Schema.org still helps, yet what truly matters is that your content is readable, crawlable and refreshable for the LLM that now greets the user.
The assistant is the storefront; your page is the warehouse.
Treat every paragraph like an API response, every price update like a feed, every review like reputation score.
8. Monday-morning checklist
Here’s what you can do next:
- Open your robots.txt in a browser — if you see Disallow: / for GPTBot, CCBot, or Anthropic-ai, fix it.
- Check your server logs or dashboard for AI user-agents. Identify rate limits, errors and more.
- Ensure XML sitemaps are citated in your robots.txt, and that they reflect changes within hours.
- Switch critical pages to server-side rendering (or static generation). Yes, AI bots can’t see client-side rendered content for now.
- List proprietary data assets sorted by update frequency; build feeds for the top three.
- Draft and ship one assistant MCP. Early shelf-space still matters.
- Segment AI traffic in analytics so you can show ROI on these efforts.
Feel free to read my full guide on the topic of SEO for AI chatbots.
Closing thought
The history of the Internet is one of relentless abstraction. First we abstracted away printing presses, then delivery trucks, then storefronts. Large-language models abstract the final mile of attention — the very act of reading, searching, comparing.
If users increasingly begin (and sometimes end) their journeys inside a dialogue, the quality of your schema markup is table-stakes. Survival depends on whether the model needs you: unique data, trusted execution, or real-world experience.
Everything else is up for grabs.
¹ All credit for the terminology and original insight on Aggregation Theory to Ben Thompson, Stratechery.