Cómo los grandes modelos de lenguaje están redibujando silenciosamente la cadena de valor de Internet — y qué deberían hacer las empresas a continuación
La Aggregation Theory de Ben Thompson (Stratechery, 2015 y 2017) explicó por qué las empresas que controlan la demanda — Google, Facebook, Amazon — acabaron acumulando todo el poder una vez que la web hizo la distribución gratuita.¹ Hoy, los grandes modelos de lenguaje (LLMs) llevan esa lógica un paso más allá: hacen que la producción de texto genérico, imágenes e incluso código sea prácticamente gratuita. Ese cambio obliga a cada web, servicio y marketplace a hacerse una pregunta directa:
¿Somos un input fácilmente reemplazable para alguien, o somos el endpoint insustituible al que una IA necesita llamar?
1. De "el contenido es el rey" a "el contenido es contexto"
Durante un cuarto de siglo, los motores de búsqueda recompensaron el volumen. Publica otro listicle de "10 mejores CRMs", consigue algunos backlinks, compra anuncios de búsqueda o retargeting — y ya tenías negocio. Los LLMs rompen ese pacto. Cuando ChatGPT, Gemini o Perplexity pueden sintetizar una respuesta convincente bajo demanda, el valor marginal de otro artículo más cae hacia cero.
Eso no mata la información; simplemente desplaza el valor hacia arriba, hacia activos que los modelos no pueden alucinar ni reemplazar fácilmente:
- Datos únicos y dinámicos — ubicaciones de trenes en tiempo real, inventario de hoteles por hora, futuros de trigo de mañana.
- Relaciones directas con el cliente — reservas, logins, pagos que el modelo no puede completar por sí solo.
- Servicios físicos o altamente especializados — un dentista, un electricista, un restaurante con tres estrellas Michelin.
Cualquier otro intermediario corre el riesgo de ser absorbido por la caja de respuestas.
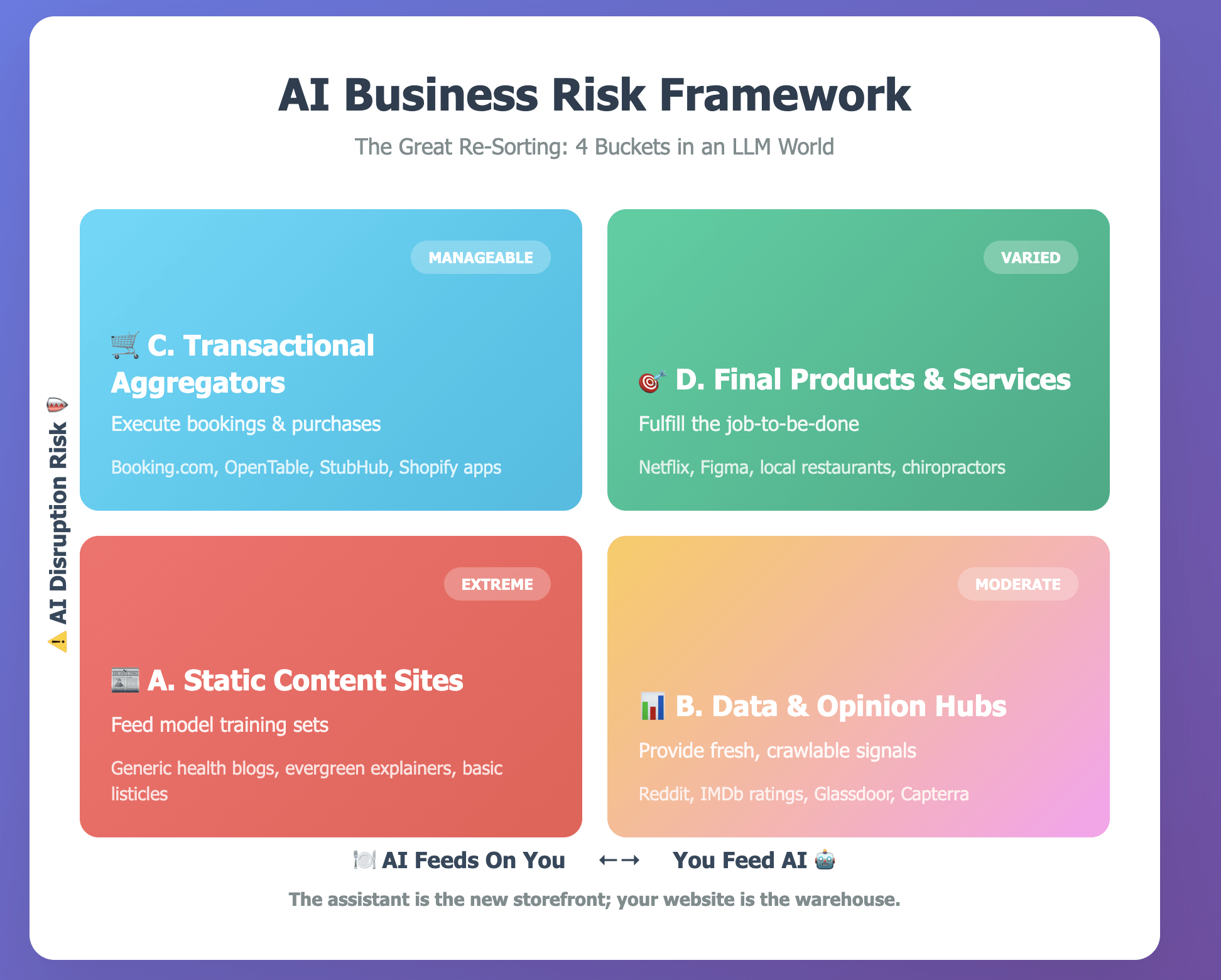
2. Cuatro categorías en un mundo de LLMs
Piensa en los negocios de la web como cuatro categorías aproximadas. Las etiquetas son mías, pero la lógica subyacente sigue el marco de Thompson.
Categoría
Rol frente a los LLMs
Ejemplos típicos
Perfil de riesgo
A. Sitios de contenido estático
Alimentan los conjuntos de entrenamiento; las respuestas se sintetizan directamente
Blogs genéricos de salud, explicaciones evergreen
Extremo — el tráfico y los ingresos publicitarios decaen primero, los ingresos después
B. Hubs de datos y opiniones
Proporcionan señales frescas y rastreables que los modelos no pueden inferir
Capterra, Glassdoor, Reddit, puntuaciones de IMDb
Moderado — deben mantenerse como los más frescos y confiables
C. Agregadores transaccionales
Complementan al modelo ejecutando la reserva, compra o contratación
Booking.com, OpenTable, StubHub, apps del marketplace de Shopify
Manejable — la intención se concentra; la competencia se intensifica
D. Productos y servicios finales
En última instancia cumplen el job-to-be-done del usuario
Netflix, Figma, un quiropráctico local, un hotel boutique
Variable — los servicios físicos son duraderos; las utilidades digitales enfrentan riesgo de copia (ver Stack Overflow)
La categoría D no es un puerto seguro permanente. Stack Overflow es el producto — pero Claude Code o la autocompleción tipo Copilot le van erosionando su razón de existir. Por el contrario, un restaurante de barrio enfrenta una presión diferente: la IA puede redistribuir la demanda ("Resérvame el bar de tapas mejor valorado a menos de dos kilómetros"), pero un modelo de lenguaje no va a estar friendo calamares por ahora.
3. Una mini-historia: cuando el formulario de registro se muda a ChatGPT
Vercel — una empresa de herramientas para desarrolladores adorada por su plataforma de hosting Next.js — compartió recientemente en su blog que uno de cada diez nuevos registros llega directamente desde las respuestas de ChatGPT. Un diez por ciento de nuevos usuarios llega a través de una interfaz conversacional que no existía hace más de 18 meses. Ese único dato captura la reordenación:
- La fase de investigación se está comprimiendo dentro del chatbox.
- El traspaso ya no pasa por Google Search, sino que irá a través de una llamada MCP.
- El ganador es el servicio en el que el modelo confía para cumplir la intención.
Si una empresa tan técnica como Vercel ve un 10% de conversiones desviadas hacia la capa de IA tan rápido, cualquier marca de consumo, B2B o servicios locales debería asumir que su funnel es el siguiente.
4. Por qué la frescura supera a la mera autoridad
El SEO clásico veneraba el PageRank. Las respuestas de los LLMs premian la recencia más estructura. Por eso los commits de GitHub, los precios de vuelos en tiempo real o un hilo de Reddit publicado hace treinta minutos aparecen en las respuestas con más frecuencia que una entrada polvorienta de la Encyclopaedia Britannica.
Esta es también la razón por la que xAI se está asociando con Telegram en un acuerdo que parece no tener sentido. Los front-ends con alto engagement tienen una gran demanda en el mundo de los LLMs. X es clave para la información en tiempo real, pero tiene pocos usuarios.
Si tus datos cambian, la capa de recuperación tiene que consultarte cada vez (de hecho lo hacen, revisa tus archivos de log). Si nunca cambian — citas de Aristóteles, la review de colchones del año pasado — se absorben una vez y se olvidan.
5. Estrategia, categoría por categoría
5.1 Editores de contenido estático
Deja de producir píxeles indiferenciados. Pivota hacia datos propietarios (encuestas originales, tests de laboratorio, colaboraciones académicas) y licéncialos o expónlos a través de una API.
5.2 Hubs de datos y opiniones
Monetiza el valor indirecto: las citas son los nuevos backlinks. Cobra a los proveedores por "salud de visibilidad en LLMs" incluso cuando los clics de enlaces azules se reducen. Añade herramientas interactivas que los chatbots no pueden replicar inline.
5.3 Agregadores transaccionales
Profundiza la complejidad de la "última milla" — niveles de fidelización, seguros complementarios, devoluciones sin fricción. Negocia inventario o precios exclusivos para que el asistente tenga que derivar hacia ti.
5.4 Productos y servicios finales
Instrumenta la percepción pública: documentación estructurada, changelogs, podcasts de thought-leadership y páginas de Wikipedia son materia prima para las respuestas. Ofrece MCPs oficiales para que los LLMs los consuman y así tu servicio sea el ejecutor por defecto.
6. "Pero nosotros somos el producto — seguro que estamos a salvo, ¿no?"
No necesariamente. Stack Overflow se enfrenta a una sustitución existencial; Shutterstock combate a Midjourney. El mundo físico es más seguro pero no inmune — la compresión de precios llega incluso cuando el servicio en sí sigue siendo irremplazable.
Piensa en el riesgo así:
- Riesgo de sustitución para utilidades puramente digitales.
- Riesgo de margen para proveedores físicos o especializados (restaurantes, fontaneros, arquitectos) a medida que los asistentes comparan precios en nombre del usuario.
- Riesgo de distribución para todos — porque el front-end se ha movido.
7. El cambio de interfaz: los modelos de IA son tu nuevo front-end
Hace unos años, en los congresos de SEO se decía: "Algún día pasaremos todos nuestros datos estructurados directamente al motor de búsqueda vía Schema.org." Teníamos razón a medias. Sí estamos entregando datos a las máquinas — pero vía scraping 24/7, no solo con JSON-ld limpio. Schema.org sigue ayudando, pero lo que realmente importa es que tu contenido sea legible, rastreable y actualizable para el LLM que ahora recibe al usuario.
El asistente es el escaparate; tu página es el almacén.
Trata cada párrafo como una respuesta de API, cada actualización de precio como un feed, cada reseña como una puntuación de reputación.
8. Checklist para el lunes por la mañana
Esto es lo que puedes hacer a continuación:
- Abre tu robots.txt en el navegador — si ves Disallow: / para GPTBot, CCBot o Anthropic-ai, corrígelo.
- Revisa los logs de tu servidor o dashboard en busca de user-agents de IA. Identifica límites de rate, errores y más.
- Asegúrate de que los XML sitemaps estén citados en tu robots.txt y que reflejen los cambios en cuestión de horas.
- Pasa las páginas críticas a renderizado del lado del servidor (o generación estática). Sí, los bots de IA no pueden ver contenido renderizado en el cliente por ahora.
- Haz una lista de tus activos de datos propietarios ordenados por frecuencia de actualización; crea feeds para los tres primeros.
- Crea y publica un MCP para asistentes. El espacio inicial todavía importa.
- Segmenta el tráfico de IA en analytics para poder demostrar el ROI de estos esfuerzos.
Si quieres profundizar, puedes leer mi guía completa sobre SEO para chatbots de IA.
Reflexión final
La historia de Internet es una de abstracción imparable. Primero abstraímos las imprentas, luego los camiones de reparto, luego los escaparates. Los grandes modelos de lenguaje abstraen la última milla de la atención — el acto mismo de leer, buscar, comparar.
Si los usuarios cada vez más empiezan (y a veces terminan) sus recorridos dentro de un diálogo, la calidad de tu marcado schema es el mínimo exigible. La supervivencia depende de si el modelo te necesita: datos únicos, ejecución de confianza o experiencia en el mundo real.
Todo lo demás está en juego.
¹ Todo el crédito por la terminología y la idea original de la Aggregation Theory para Ben Thompson, Stratechery.